
刘斌认为,在多模态模型推出后,对话的方式与原来纯文本交互不同,会从异步变为实时双工交互,实现了很大的飞跃。但在*终应用落地的过程中,依然存在很多客户痛点,比如在实际应用场景中,用户的设备通常无法像发布会演示的那样一直处于固定网络与物理环境下,大部分ConversationalAIAgent的使用场景是随机的,也就是可能会发在AnytimeAnywhere,比如在开车送完孩子上学之后,这就对大模型实时语音对话中的低延时传输、网络优化等提出了考验。一般来说,延迟在1.7秒内会让人感觉自然,2秒多、3秒则会让人觉得卡顿、反应慢。
其次在模型交互中能否支持智能打断以及主动交互也是用户非常关注的一个关键点。要做到这些,除了模型能力,在应用落地方面,需要端到端的能力支持,不仅需要成熟的VAD技术来实现自由打断,更需要一整套的音频高级算法来支撑实现优雅打断,从而实现用户体验*好的人模对话,当然也需要应对不同的物理环境、复杂的网络环境、PC、手机以及各类IoT终端等。
语音对线ms:针对大模型语音交互中普遍存在响应时间长的痛点,声网自研的SD-RTN实时传输网络可以实现全球范围的低延时音视频传输,目前可做到语音对线ms,并进一步通过更快速的LLM推理首字耗时、低延迟流式TTS、同机部署等一系列技术手段,保证对话的实时性与流畅性,达到近似人与人之间日常对话停顿与间隔。
支持智能打断:开发者在构建AI应用场景时,会将能否支持随时打断也成为衡量大模型智能化的重要指标。声网自研的AIVAD技术,适九游娱乐文化 九游app官方入口应人类对话的停顿、语气和对话节奏,支持AI对话过程中随时打断。同时,声网的解决方案还深度优化AI角色,*大程度保留情绪情感等关键信息,超拟人真实音色丰富通话体验。
支持30000+移动终端:在大模型的应用落地中,不同的终端设备、操作系统等也会带来不一样的体验,声网的音视频SDK经过不断的迭代升级,可以支持30多个平台框架、30000多终端机型及各种操作系统,包括各类IoT设备终端;
*的音频处理:在人与人音视频通话的过程中,环境噪音是经常遭遇的一大痛点,影响沟通效率。在GenAI场景中,环境噪音同样无法避免。声网具备业界*的音频3A能力,提供AI回声消除、AI智能降噪、背景人声过滤、音乐检测/过滤、主讲人声纹锁定等自研音频技术,即使在商场、地铁站等嘈杂环境中,也能保证AI对话过程不受影响。
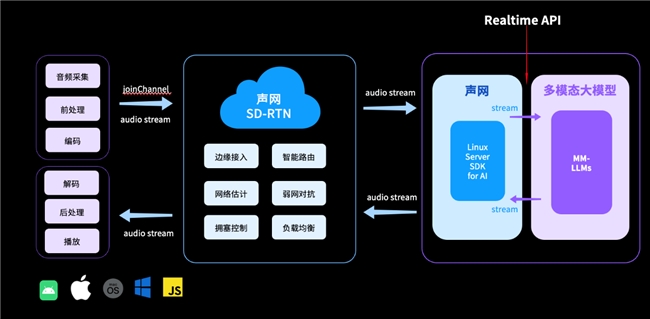
在与大模型厂商合作的过程中,声网也发现想要提升大模型落地的实用性,现有RTE技术栈和基础设施仍有大量改进空间。刘斌表示,只有通过不断的演进,大模型才有机会在各种场景、形态下大规模参与到和人的语音对话中,大模型也将基于云、设备端、边缘的多维度参与与协作。基于这些能力的改进和普及,未来RTE将成为GenAI时代AI基础设施(AIInfra)的关键部分。
同时,GenAI也在驱动RTE实时互动的技术变革与体验革新,在人与人的实时互动中,声网一直致力于实现从QoS服务质量到QoE体验质量的技术变革,在体验层面也从“听得到“变为“听得清”。而在人与AI的实时互动中,为了进一步增强体验,RTE的技术变革也演变为AIQoE甚至多模态AIQoE,这背后就包含了声网自研的AIVAD能力、降噪能力及网络优化等一系列技术能力,以使得人与AI的对话更符合实际情况,大模型也从理解内容,变成理解对话人的心理、情绪,*终理解对话时的人类意图,*后实现从“听得懂“到“听「得心」”的体验革新。


























